Building a Complementary Data Science Team
This post was originally published on Medium
I’m the Director of Data Science at EAB, a firm that provides best-practices research and enterprise software for colleges and universities. My team is responsible for the predictive models and other advanced analytics that are part of the Student Success Collaborative product that’s used by academic advisors and other campus leadership. We’re hiring data scientists, and I wanted to publicly say a few things about the roles we have advertised. (Note that EAB is part of a public company and is in a competitive market, so there are obviously things I’m not saying!)
The most important point is that data scientists specialize, so look for the specializations. My co-authors and I made this point in our 2012 e-book Analyzing the Analyzers, and the folks at Mango Solutions are burning up Twitter with their self-service tool for identifying data science strengths and weaknesses.
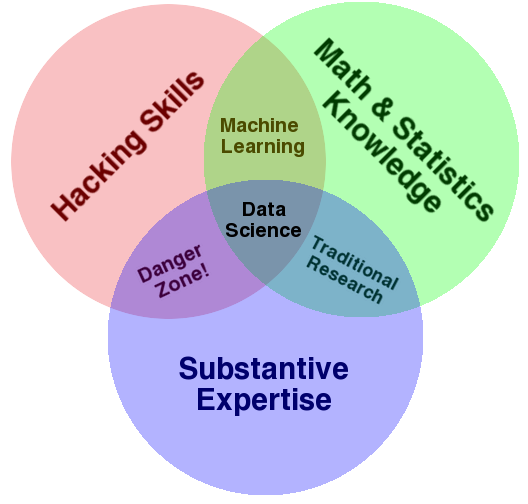 Drew Conway’s Data Science Venn Diagram — Source.
Drew Conway’s Data Science Venn Diagram — Source.
A related point is that existing framing devices can help you balance a team. Drew Conway’s Venn Diagram remains a great way to think about Data Science aptitude. Combine people with strengths in each part of the diagram, who know enough to collaborate effective and make each other stronger, and you don’t need a team of unicorns with 3 PhDs each.
I suspect the details of the framing device are less important than the fact that you have one. It forces you to think about variety and complementary skills, and how people work together to solve problems and build systems.
At EAB, we have four career tracks for data scientists — Research, Engineering, Statistical Programming, and Management. Our new roles supplement our existing team by adding several new people, each with different capabilities and seniority.
At a Senior level, we’re looking for a Statistical Programmer-track person who is particularly strong in algorithm development and implementation, perhaps a straight-up Computer Scientist. Think of the “Machine Learning” area in Drew’s diagram. As we look to expand the classes of statistical techniques that we use, we need more people who know the academic literature and can figure out exactly what technical solution will let us build and scale high-quality models. Interested? Please apply!
A little less senior, we’re also looking for a Researcher who can help us apply domain knowledge even more effectively in our analyses, models, and systems. Some software, data visualization, and statistical skills required — maybe a quantitative Social Scientist pivoted into industry? The upper edge of the Substantive Expertise area. Sound like you? Please apply!
I strongly believe that a Data Science team should do all of the Data Science, including building and owning models in production. So, last but not least, we’re looking for another Engineering-focused data scientist, who can help us build model frameworks, data tools, workflow tools, and more. This role can be junior or even entry-level, but we do need programming skills, statistical thinking skills, and some sort of portfolio. Programmer and recent data science boot camp grad, perhaps? Please apply!
Of course, as we talk to people, learn what they’re good at and excited about, and what they bring, we may end up with a different mix of skills. But regardless, they’ll cover the space of data scientists, will provide different perspectives and skills, and will help us own our own tools and systems so that we can move and learn quickly.