IZE - Revisiting a hierarchical search technology from the PC era
Sometimes revisiting old technology is the best way to understand how we got where we are -- and to see what alternative paths might have looked like. This is the first in a series of posts about IZE, a DOS-era personal information manager that I think has some interesting lessons for modern search and discovery.
I'll admit my interest in IZE isn't purely academic. My father was a co-founder of the company that published it, and a cousin of his was the inventor of the underlying technology, which the company acquired. So I grew up with IZE around the house, and owned the polo shirt. That said, I think it's genuinely interesting on its own merits, and I'll try to make the case for that here.
What was IZE?
IZE splash screen
IZE was a DOS application introduced in the late 1980s. It was, broadly speaking, a personal information manager -- a word processor with organizational and information retrieval features layered on top. Think of it as a precursor to tools like Obsidian, but running on a 286 with a monochrome monitor and no internet connection.
The innovation that set IZE apart was its approach to search and navigation: an interactive, dynamically-generated hierarchy. When you searched your document collection, IZE didn't just return a flat list of matching results. It built a table of contents on the fly, organized by the most frequently co-occurring keywords in your result set. Drill into a branch of that hierarchy, and IZE regenerated it based on the narrowed set of documents. The keywords could be selected manually or semi-automatically, depending on how much you wanted to guide the process.
It was a novel attempt to give users context for navigating a text collection and refining their queries -- years before faceted search became a subject of serious academic study, and two decades before it became the default pattern for e-commerce and enterprise search. A Search UI has two jobs -- helping people find relevant information, and educating them about the structure of the information space. IZE was a surprisingly good for the era attempt at the latter.
How good? Although its sales were not strong enough to sustain the company, one enthusiastic user got an IZE logo tattoo!
What it looked like
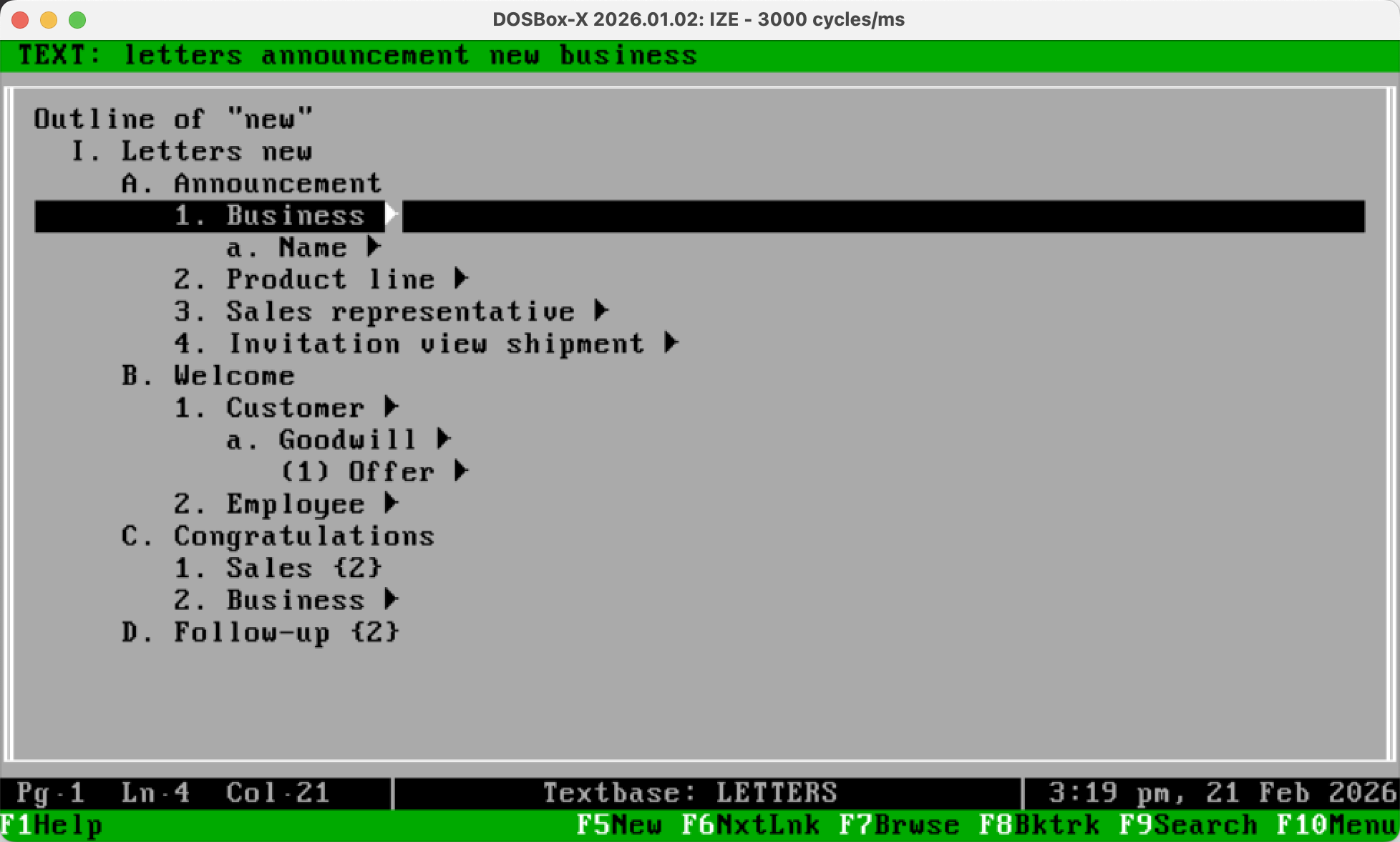
IZE screenshot
The interface was text-mode, as you'd expect for a late-80s DOS application. The hierarchy appeared as an indented outline, and a well-designed set of keyboard shortcuts made it easy to navigate to find the most relevant documents. It was surprisingly fluid for the era.
In the screenshot above, from a tutorial textbase of business letters, you can see that I'd searched for "new", and IZE generated a hierarchy of documents that contained that word, organized by the most frequently co-occurring keywords. The cursor is on "new business announcement letters". It's very fast to see what sorts of "new letters" are available, and to navigate to the ones you want.
Why this matters now
The question of how best to help users orient themselves within a large document collection (or e-commerce catalog) -- and how to help them refine their queries -- is still a topic of research and experimentation. Faceted search, which became dominant in the 2000s and 2010s, addresses part of this. But facets require a pre-defined taxonomy, and they work best when the attribute space is relatively flat and well-understood by the users. IZE's approach was different: it derived structure from the keywords tagged in the documents themselves, dynamically, in response to the user's current query.
I think it's worth understanding that idea carefully before asking whether modern tools -- vector search, topic models, LLM-generated labels -- could do something similar, or better.
Coming up in this series
This post is just the introduction. Here's what I'm planning to cover:
- How IZE really worked -- patents, limits, and Esther Dyson's take
- What came after IZE? Three Domains, Three Answers
- Could we build IZE again? A live demo
- GeneralIZE -- How else could IZE's hierarchies be generated?
- IZE meets AI -- semantic search, smarter labels, and agentic orientation
I'll update this post with links to the follow-ups as they're published.
Notes: This post was primarily human-authored, with AI assistance for research, editing, and organization. The AI filled a Secondary author role. The core ideas and final voice are mine. Thanks to Ed Harris for feedback and valuable context.